



A lightweight semantic VSLAM approach based on adaptive thresholding and speed optimization
-
摘要:
视觉同步定位与地图构建(VSLAM)是一种利用视觉等传感器来获取未知环境信息的技术,广泛应用于无人驾驶、机器人、增强现实等领域。然而,室内场景下的VSLAM对动态对象进行像素级的语义分割存在较高的计算开销,并且光照变化使得动态物体的外观也发生变化,导致其与静态环境产生遮挡或混淆。针对以上问题,提出了一种基于自适应阈值和速度优化的轻量化语义VSLAM模型。采用了轻量化的一阶段目标检测网络YOLOv7-tiny,结合光流算法,有效地检测了图像的动态区域,并对不稳定特征点进行了剔除。同时,特征点提取算法基于输入图像的对比度信息,自适应地调整阈值。结合二进制词袋与局部建图线程精简的优化方法,加快了加载和匹配速度,提高了系统在室内动态场景下的运行速度。实验结果表明:所提算法在室内高动态场景下能够有效地剔除动态特征点,提高了相机的定位精度。在运行速率方面平均处理速度达到了19.8 FPS,在实际场景下可以满足实时性的需求。
-
关键词:
- VSLAM /
- 动态场景 /
- YOLOv7-tiny /
- 自适应阈值 /
- 特征点
Abstract:Visual simultaneous localization and mapping (VSLAM) is a technology that utilizes visual and other sensory sensors to acquire information about unknown environments. It is widely applied in fields such as autonomous driving, robotics, augmented reality, and more. However, pixel-level semantic segmentation of dynamic objects entails high computing costs for indoor visual SLAM, and variations in lighting make dynamic items appear more difficult to see, potentially causing occlusions or confusion with the static surroundings. To address these challenges, a lightweight semantic VSLAM model is proposed, which is based on adaptive thresholding and velocity optimization. Initially, a lightweight one-stage object detection network, YOLOv7-tiny, is utilized in conjunction with the optical flow algorithm to effectively detect dynamic regions within images and filter out unstable feature points. Additionally, the feature point extraction algorithm dynamically adjusts the threshold based on the contrast information of the input images. Moreover, the combination of a binary bag-of-words method with a simplified optimization technique for local mapping threads improves the system's loading and matching speed in indoor dynamic scenarios. Experimental results show that the proposed algorithm can effectively eliminate dynamic feature points in indoor high-dynamic scenes, improving the positioning accuracy of the camera. The average processing speed reaches 19.8 frames per second (FPS), meeting real-time requirements in practical scenarios.
-
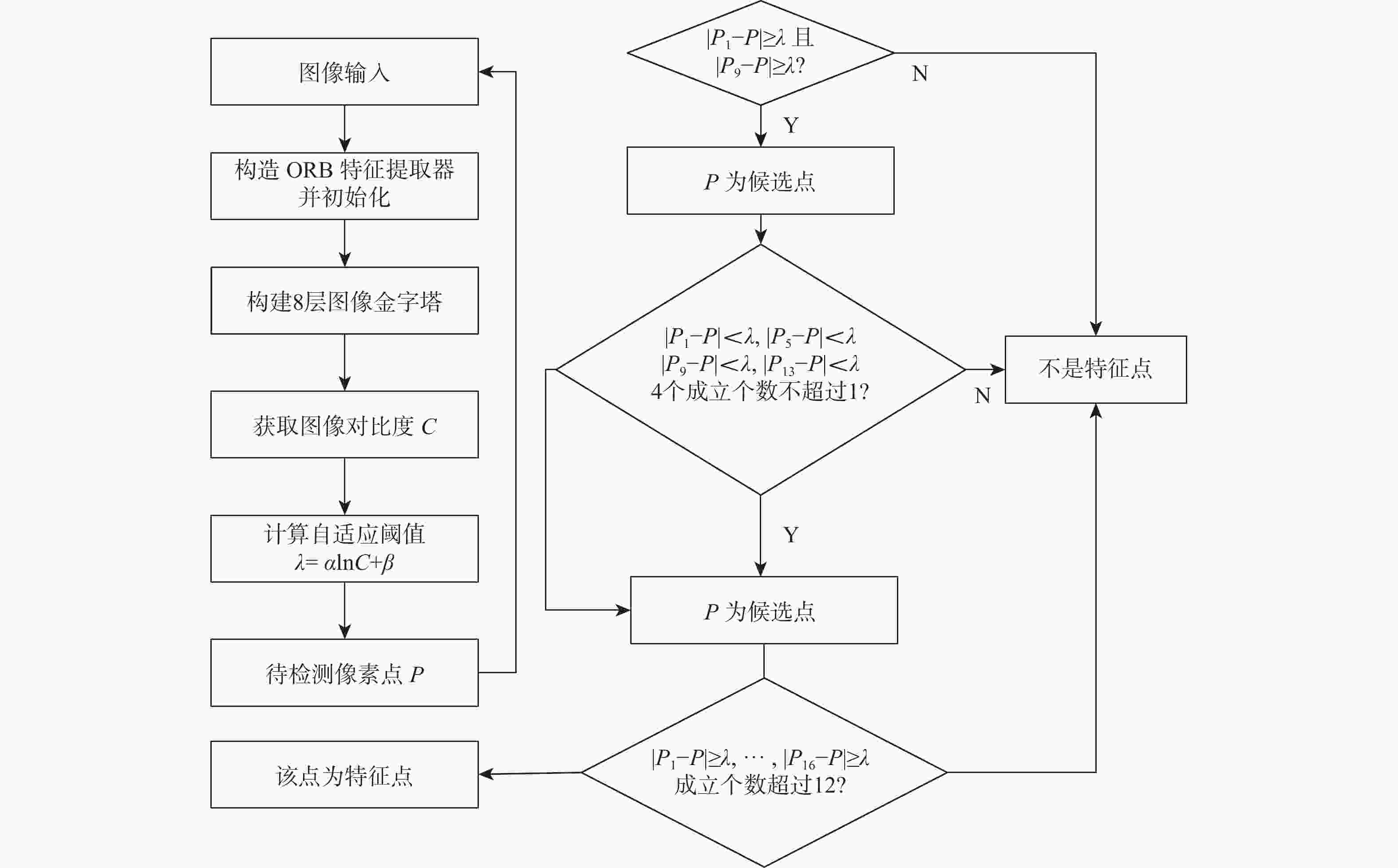
图 3 基于自适应阈值的特征点提取算法流程
Figure 3. Based on adaptive threshold feature point extraction algorithm flow chat

图 6 改进前后特征点提取效果对比图
Figure 6. Comparison of feature point extraction effect before and after improvement
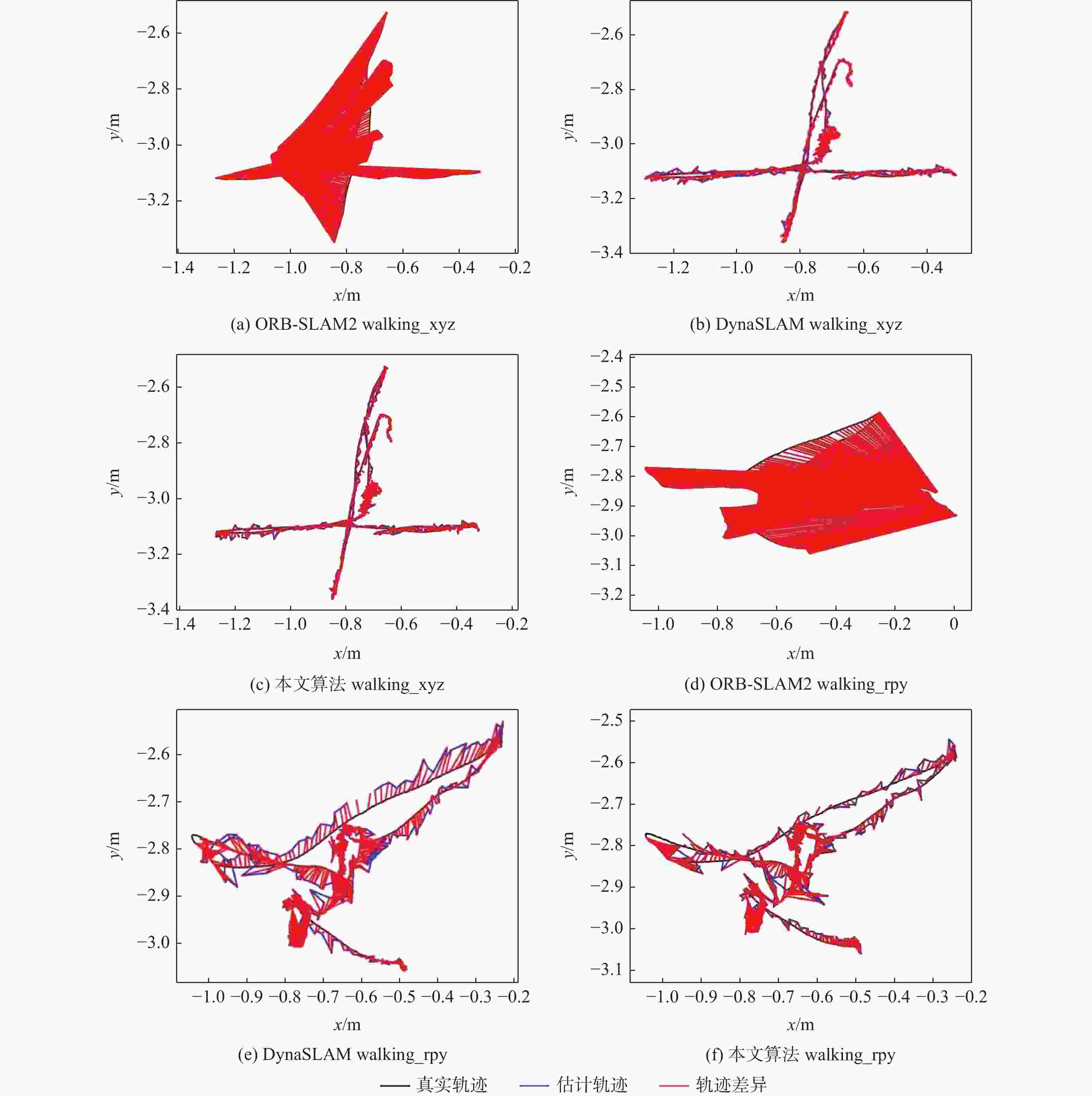
图 7 高动态场景下估计轨迹和真实轨迹对比
Figure 7. Comparison of real and estimated trajectories in high dynamic scenes

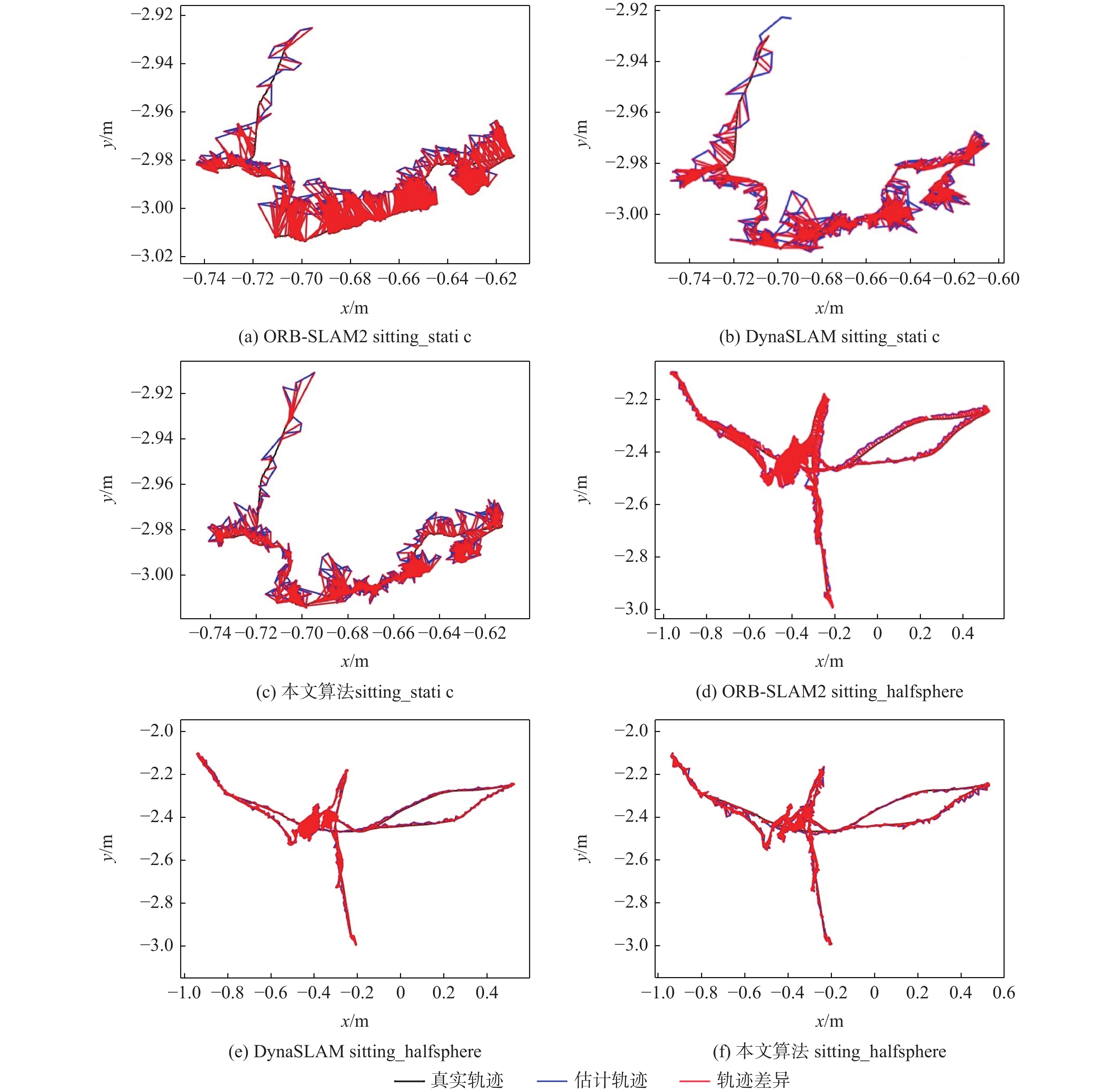
图 8 低动态场景下估计轨迹和真实轨迹对比
Figure 8. Comparison of real and estimated trajectories in low dynamic scene
表 1 实验环境
Table 1. Experimental environment
配置名称 配置情况 处理器 Intel(R) Core(TM) i9-10900x CPU@3.70 GHz 显卡 NVIDIA GeForce RTX 3080 操作系统 Ubuntu 18.04 深度学习框架 Keras 2.0.9、TensorFlow-gpu 1.14.0  下载: 导出CSV
下载: 导出CSV
表 2 不同词袋性能对比
Table 2. Performance comparison of different BOW
性能 词袋空间大小/MB 平均加载时间/ms 原有词袋 145.3 8 289.01 二进制词袋 42.3 267.92 注:二进制词袋比原有词袋在词袋空间和平均加载时间分别提升了70.89%、96.77%。
下载: 导出CSV
表 3 不同线程各部分耗时对比
Table 3. Time-consuming comparison of various parts of different threads
线程 模块 用时/ms 标准差/ms 跟踪线程 特征提取 17.78 3.85 位姿估计 2.87 1.31 整体耗时 33.22 13.99 局部地图构建线程 关键帧插入 17.96 8.11 地图点创建 91.17 30.59 局部BA优化 458.52 319.41 总体耗时 609.71 368.44
下载: 导出CSV
表 4 跟踪线程处理单帧图片用时对比
Table 4. Time-consuming comparison of tracking thread processing single frame
数据集
名称[28]不同模型处理单帧图片耗时/ms YOLOv3-
SLAM[29]YOLOv4-
SLAM[30]DynaSLAM[17] 本文
算法fr3_s_static 55.96 55.54 1 444.07 25.57 fr3_s_xyz 61.36 61.90 1 616.43 42.36 fr3_s_half 70.43 66.75 1 534.07 55.78 fr3_s_rpy 63.69 58.57 1 491.33 41.89 fr3_w_static 83.42 82.97 1 676.27 62.32 fr3_w_xyz 89.47 87.60 1 718.56 69.37 fr3_w_half 95.11 90.74 1 683.11 50.36 fr3_w_rpy 82.57 72.72 1 519.81 54.78
下载: 导出CSV
表 5 对比度降低和亮度减少的定位效果
Table 5. Positioning effect of contrast reduction and brightness reduction
m 数据集名称 未加入阈值法 加入阈值 fr3_walking_static 0.184 179 0.179 079 fr3_walking_xyz 0.023 520 0.021 872
下载: 导出CSV
表 6 对比度降低和亮度增加的定位效果
Table 6. Positioning effect of contrast reduction and brightness increase
m 数据集名称 未加入阈值 加入阈值 fr3_walking_static 0.209 476 0.188 325 fr3_walking_xyz 0.028 880 0.023 741
下载: 导出CSV
表 7 绝对轨迹误差的RMSE对比
Table 7. RMSE comparison of absolute trajectory error
数据集名称 ORB-SLAM2[8] YOLOv3-SLAM[29] YOLOv4-SLAM[30] DynaSLAM[17] 本文算法 fr3_sitting_static 0.149 578 0.357 965 0.343 385 0.078 521 0.210 825 fr3_sitting_xyz 0.017 513 0.020 901 0.023 578 0.022 394 0.017 827 fr3_sitting_halfsphere 0.032 686 0.029 224 0.025 969 0.025 076 0.025 955 fr3_sitting_rpy 0.144 598 0.276 151 0.299 480 0.253 892 0.328 201 fr3_walking_static 2.757 299 0.261 943 0.220 086 0.124 637 0.136 923 fr3_walking_xyz 1.440 868 0.017 448 0.019 748 0.020 895 0.017 363 fr3_walking_halfsphere 0.977 844 0.041 687 0.052 667 0.030 216 0.033 667 fr3_walking_rpy 2.283 019 0.101 932 0.205 203 0.079 428 0.076 706
下载: 导出CSV
表 8 相对位姿误差的RMSE的对比
Table 8. RMSE comparison of relative pose error
数据集名称 ORB-SLAM2[8] YOLOv3-SLAM[29] YOLOv4-SLAM[30] DynaSLAM[17] 本文算法 fr3_sitting_static 0.005 814 0.006 678 0.006 538 0.006 379 0.006 153 fr3_sitting_xyz 0.011 067 0.012 211 0.012 060 0.012 741 0.011 950 fr3_sitting_halfsphere 0.011 109 0.028 343 0.030 124 0.018 423 0.025 955 fr3_sitting_rpy 0.016 804 0.016 104 0.016 180 0.020 151 0.016 260 fr3_walking_static 0.025 154 0.009 937 0.009 911 0.008 539 0.009 858 fr3_walking_xyz 0.032 623 0.015 785 0.015 911 0.014 958 0.015 203 fr3_walking_halfsphere 0.068 258 0.016 998 0.017 734 0.015 907 0.016 233 fr3_walking_rpy 0.029 868 0.022 164 0.022 131 0.024 993 0.022 125
下载: 导出CSV
-
[1] CHEN W F, SHANG G T, JI A H, et al. An overview on visual SLAM: from tradition to semantic[J]. Remote Sensing, 2022, 14(13): 3010. doi: 10.3390/rs14133010 [2] AI Y B, RUI T, LU M, et al. DDL-SLAM: a robust RGB-D SLAM in dynamic environments combined with deep learning[J]. IEEE Access, 2020, 8: 162335-162342. doi: 10.1109/ACCESS.2020.2991441 [3] YU L J, YANG E F, YANG B Y. AFE-ORB-SLAM: robust monocular VSLAM based on adaptive FAST threshold and image enhancement for complex lighting environments[J]. Journal of Intelligent & Robotic Systems, 2022, 105(2): 26. [4] NEWCOMBE R A, LOVEGROVE S J, DAVISON A J. DTAM: dense tracking and mapping in real-time[C]//Proceedings of the 2011 International Conference on Computer Vision. Piscataway: IEEE Press, 2011: 2320-2327. [5] FORSTER C, PIZZOLI M, SCARAMUZZA D. SVO: fast semi-direct monocular visual odometry[C]//Proceedings of the 2014 IEEE International Conference on Robotics and Automation. Piscataway: IEEE Press, 2014: 15-22. [6] DAVISON A J, REID I D, MOLTON N D, et al. MonoSLAM: real-time single camera SLAM[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(6): 1052-1067. doi: 10.1109/TPAMI.2007.1049 [7] KLEIN G, MURRAY D. Parallel tracking and mapping for small AR workspaces[C]//Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality. Piscataway: IEEE Press, 2007: 225-234. [8] MUR-ARTAL R, TARDÓS J D. ORB-SLAM2: an open-source SLAM system for monocular, stereo, and RGB-D cameras[J]. IEEE Transactions on Robotics, 2017, 33(5): 1255-1262. doi: 10.1109/TRO.2017.2705103 [9] CAMPOS C, ELVIRA R, RODRÍGUEZ J J G, et al. ORB-SLAM3: an accurate open-source library for visual, visual–inertial, and multimap SLAM[J]. IEEE Transactions on Robotics, 2021, 37(6): 1874-1890. doi: 10.1109/TRO.2021.3075644 [10] SHEN X Q, CHEN L H, HU Z H, et al. A closed-loop detection algorithm for online updating of bag-of-words model[C]// Proceedings of the 2023 9th International Conference on Computing and Data Engineering. New York: ACM, 2023: 34-40. [11] CHENG Y H, WANG J. A motion image detection method based on the inter-frame difference method[J]. Applied Mechanics and Materials, 2014, 490-491: 1283-1286. doi: 10.4028/www.scientific.net/AMM.490-491.1283 [12] CUTLER R, DAVIS L S. Robust real-time periodic motion detection, analysis, and applications[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 22(8): 781-796. [13] KLAPPSTEIN J, VAUDREY T, RABE C, et al. Moving object segmentation using optical flow and depth information[C]//Proceedings of the Advances in Image and Video Technology. Berlin: Springer, 2009: 611-623. [14] DEROME M, PLYER A, SANFOURCHE M, et al. Moving object detection in real-time using stereo from a mobile platform[J]. Unmanned Systems, 2015, 3(4): 253-266. doi: 10.1142/S2301385015400026 [15] YU C, LIU Z X, LIU X J, et al. DS-SLAM: a semantic visual SLAM towards dynamic environments[C]//Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE Press, 2018: 1168-1174. [16] BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495. doi: 10.1109/TPAMI.2016.2644615 [17] BESCOS B, FÁCIL J M, CIVERA J, et al. DynaSLAM: tracking, mapping, and inpainting in dynamic scenes[J]. IEEE Robotics and Automation Letters, 2018, 3(4): 4076-4083. doi: 10.1109/LRA.2018.2860039 [18] FU Y X, HAN B, HU Z H, et al. CBAM-SLAM: a semantic SLAM based on attention module in dynamic environment[C]//Proceedings of the 2022 6th Asian Conference on Artificial Intelligence Technology. Piscataway: IEEE Press, 2022: 1-6. [19] CAI D P, HU Z H, LI R Q, et al. AGAM-SLAM: an adaptive dynamic scene semantic SLAM method based on GAM[C]//Proceedings of the Advanced Intelligent Computing Technology and Applications. Berlin: Springer, 2023: 27-39. [20] HE K M, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 2980-2988. [21] QI H, HU Z H, XIANG Y F, et al. ATY-SLAM: a visual semantic SLAM for dynamic indoor environments[C]//Proceedings of the Advanced Intelligent Computing Technology and Applications. Berlin: Springer, 2023: 3-14. [22] CHANG Z Y, WU H L, SUN Y L, et al. RGB-D visual SLAM based on Yolov4-tiny in indoor dynamic environment[J]. Micromachines, 2022, 13(2): 230. doi: 10.3390/mi13020230 [23] WANG C Y, BOCHKOVSKIY A, LIAO H M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2023: 7464-7475. [24] GONZALES R C, WINTZ P. Digital image processing[M]. Reading: Addison-Wesley Longman Publishing Co., Inc., 1987. [25] BURRI M, NIKOLIC J, GOHL P, et al. The EuRoC micro aerial vehicle datasets[J]. The International Journal of Robotics Research, 2016, 35(10): 1157-1163. doi: 10.1177/0278364915620033 [26] VISWANATHAN D G. Features from accelerated segment test (fast)[C]// Proceedings of the 10th Workshop on Image Analysis for Multimedia Interactive Services. Piscataway: IEEE Press, 2009: 6-8. [27] QADER W A, AMEEN M M, AHMED B I. An overview of bag of Words;Importance, implementation, applications, and challenges[C]//Proceedings of the 2019 International Engineering Conference. Piscataway: IEEE Press, 2019: 200-204. [28] STURM J, ENGELHARD N, ENDRES F, et al. A benchmark for the evaluation of RGB-D SLAM systems[C]//Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE Press, 2012: 573-580. [29] REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. (2018-04-08)[2023-07-25]. http://doi.org/10.48550/arXiv.1804.02767. [30] BOCHKOVSKIY A, WANG C Y, LIAO H M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. (2020-04-23)[2023-07-25]. http://doi.org/10.48550/arXiv.2004.10934. -

 下载:
下载:







 点击查看大图
点击查看大图

计量
- 文章访问数: 294
- HTML全文浏览量: 65
- PDF下载量: 45
- 被引次数: 0
