



Active deformation decision-making for four-wing variable sweep aircraft based on LSTM-DDPG algorithm
-
摘要:
针对变体飞行器主动变形控制问题,提出一种基于长短期记忆(LSTM)网络深度确定性策略梯度(DDPG)算法的智能变形控制方法;以一种串置翼构型的四翼变掠角飞行器为研究对象,利用OPENVSP软件计算其几何模型和气动参数,并建立了飞行器动力学模型;针对四翼变掠角飞行器的加速爬升过程,设计了基于LSTM-DDPG算法学习框架,并在对称变形条件下,针对纵向轨迹跟踪进行主动变形决策训练。仿真结果表明:应用于主动变形控制过程中的LSTM-DDPG算法可以快速收敛并达到更高的平均奖励,且训练获得的主动变形控制器在四翼变掠角飞行器的轨迹跟踪任务中具有良好的控制效果。
-
关键词:
- 变体飞行器 /
- 飞行控制 /
- 深度强化学习 /
- 深度确定性策略梯度 /
- 长短期记忆递归神经网络
Abstract:This paper presented an intelligent deformation control method based on the long short-term memory (LSTM) deep deterministic policy gradient (DDPG) algorithm, addressing the active deformation control challenges in variable configuration aircraft. A four-wing variable sweep aircraft with a tandem-wing configuration was studied, and its geometric model and aerodynamic parameters were calculated through OPENVSP, which was then used to establish the aircraft’s dynamics model. The LSTM-DDPG algorithm learning framework was designed for the accelerated climb process of the four-wing variable sweep aircraft. Under symmetrical deformation conditions, active deformation decision training was performed for longitudinal trajectory tracking. Simulation results show that the LSTM-DDPG algorithm applied to the active deformation control process converges quickly and achieves higher average rewards. Moreover, the trained active deformation controller exhibits good control performance in the trajectory tracking tasks of the four-wing variable sweep aircraft.
-
图 1 掠角对称变形下飞行器形态
Figure 1. Aircraft configuration under sweepback symmetrical deformation

图 3 气动系数与迎角的关系
Figure 3. Relationship between aerodynamic coefficients and angle of attack
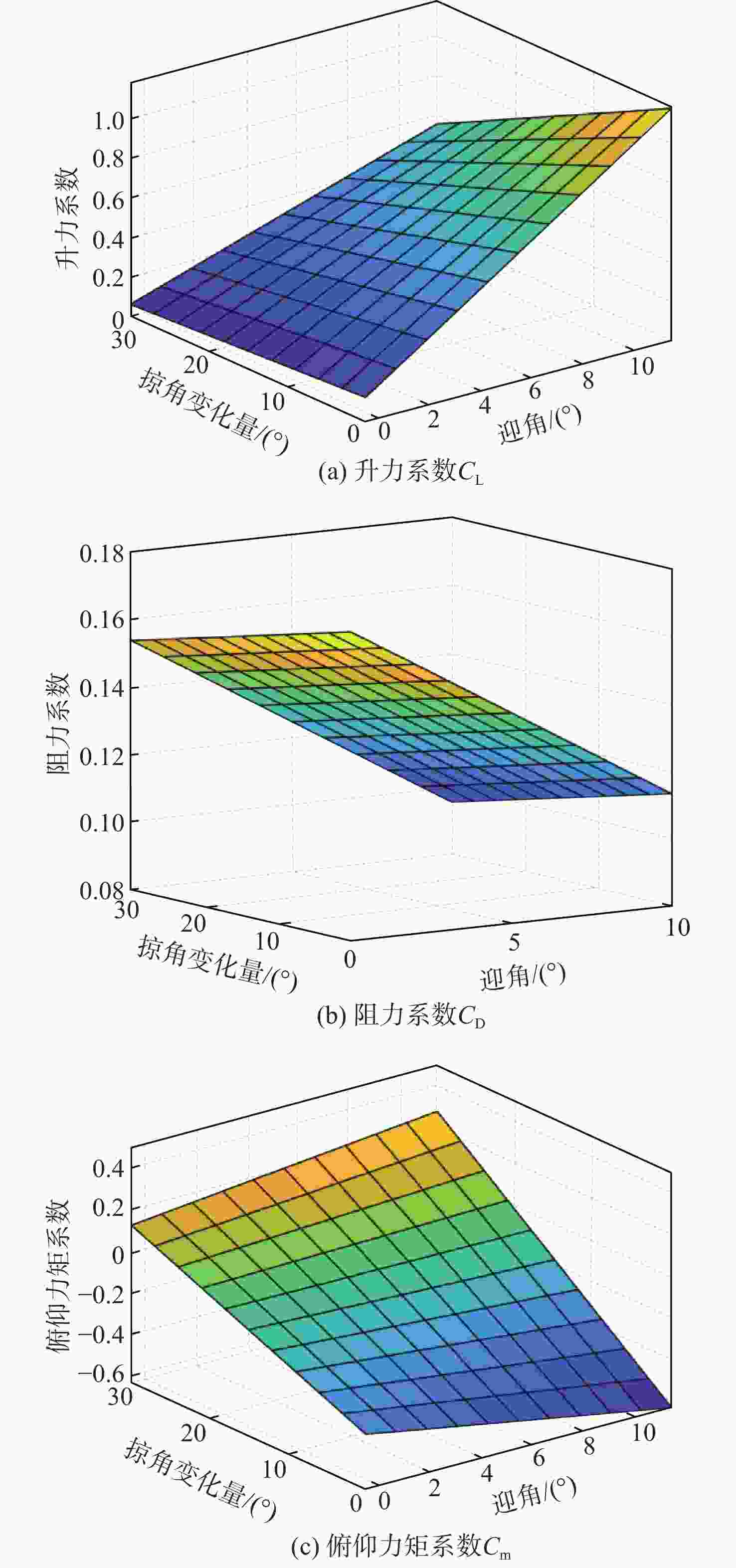
图 4 变形量和迎角对气动系数的影响
Figure 4. Effects of deformation and angle of attack on aerodynamic coefficients
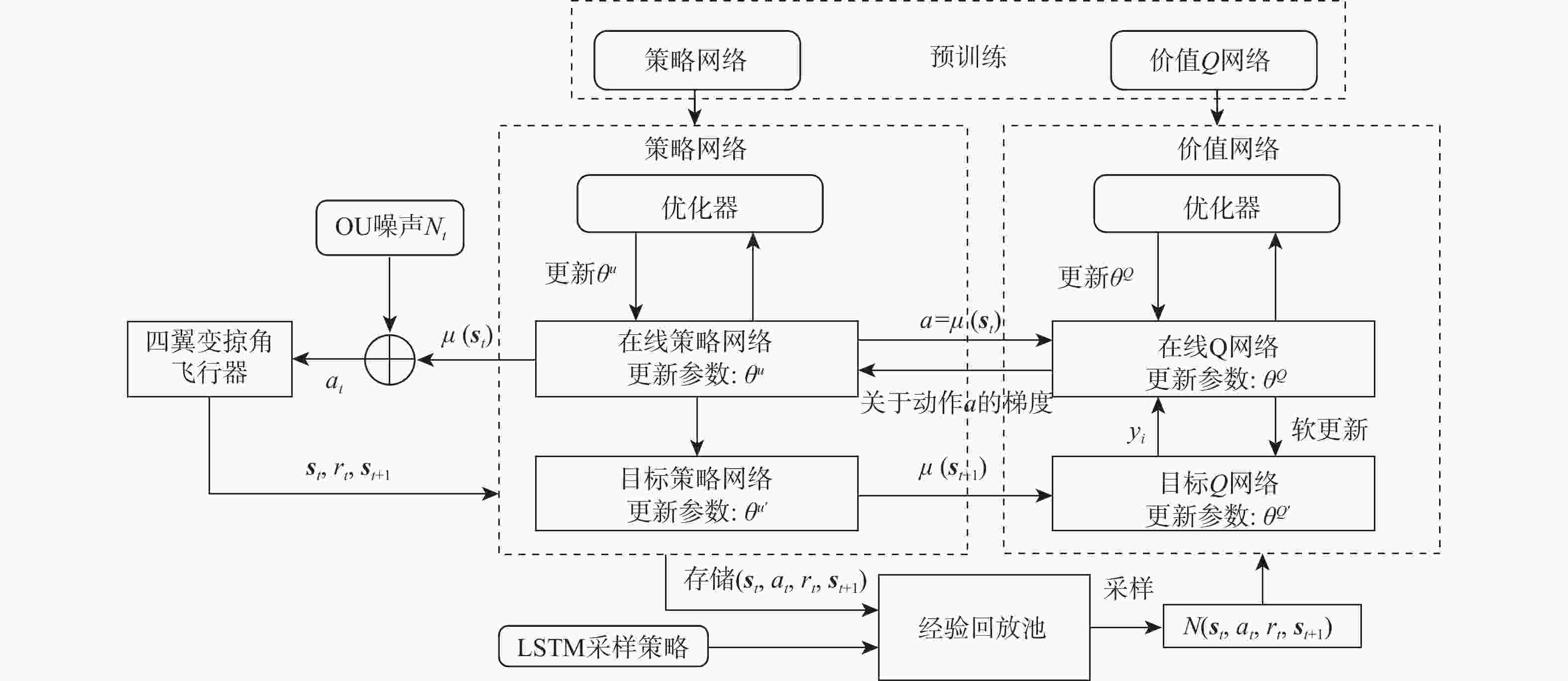
图 8 四翼变掠角飞行器LSTM-DDPG算法学习框架
Figure 8. LSTM-DDPG algorithm learning framework for four-wing variable sweep angle aircraft
表 1 四翼变掠角变体飞行器关键参数
Table 1. Key parameters of quad-wing variable sweep angle variant aircraft
参数 数值 飞行器总质量m/kg $1.668$ 质心与机翼旋转中心间距l/m $0.140$ 面Oxz与前翼旋转中心间距ac/m $0.165$ 面Oxz与后翼旋转中心间距aw/m $0.235$ 面Oxz与机翼旋转中心间距bf/m $0.040$ 机翼质量ma/kg $0.080$ 翼展b/m $0.893$ 平均气动弦长ca/m $ 0.077 $ 前后翼间距St/m $0.420$ 翼面积Sm/m2 $0.135$  下载: 导出CSV
下载: 导出CSV
表 2 奖励函数参数
Table 2. Reward function parameters
奖励函数参数 数值 ${h_{{\text{target}}}}$/${\text{m}}$ 232 ${q_{{\text{target}}}}$/(rad·s−1) 0 ${V_{{\text{target}}}}$/(m·s−1) 32 $ {\delta _h} $/m 1 $ {\delta _v} $/(m·s−1) 0.5 $ {\delta _\mu } $/rad 0.1 $ {\delta _q} $/(rad·s−1) 0.1 ($ {h_{\max }} $,$ {h_{\min }} $)/m (235,198) ($ {V_{\max }} $,$ {V_{\min }} $)/(m·s−1) (33,20) $ {q_{\max }} $/(rad·s−1) 1 $ {\alpha _{\max }} $/rad ${\text{π}} /4$
下载: 导出CSV
表 3 LSTM-DDPG算法超参数设置
Table 3. LSTM-DDPG algorithm hyperparameter settings
超参数 数值 目标网络更新率 0.001 Actor网络学习率 0.0001 Critic网络学习率 0.001 经验回放池容量 ${10^6}$ 小批量样本数 256 折扣因子 0.991 最大幕数 80000 最大步数 800 采样时间/s 0.02
下载: 导出CSV
-
[1] BARBARINO S, BILGEN O, AJAJ R M, et al. A review of morphing aircraft[J]. Journal of Intelligent Material Systems and Structures, 2011, 22(9): 823-877. doi: 10.1177/1045389X11414084 [2] GUO T H, HOU Z X, ZHU B J. Dynamic modeling and active morphing trajectory-attitude separation control approach for gull-wing aircraft[J]. IEEE Access, 2017, 5: 17006-17019. doi: 10.1109/ACCESS.2017.2743059 [3] WU Z H, LU J C, SHI J P, et al. Robust adaptive neural control of morphing aircraft with prescribed performance[J].Mathematical Problems in Engineering, 2017, 2017(1): 1401427. doi: 10.1155/2017/1401427 [4] GONG L G, WANG Q, HU C H, et al. Switching control of morphing aircraft based on Q-learning[J]. Chinese Journal of Aeronautics, 2020, 33(2): 672-687. doi: 10.1016/j.cja.2019.10.005 [5] XU D, HUI Z, LIU Y, et al. Morphing control of a new bionic morphing UAV with deep reinforcement learning[J]. Aerospace science and technology, 2019, 92: 232-243. doi: 10.1016/j.ast.2019.05.058 [6] YANG Z C, TAN J B, WANG X Q, et al. Reinforcement learning-based robust tracking control application to morphing aircraft[C]//Proceeding of the American Control Conference. Piscataway: IEEE Press, 2023: 2757-2762. [7] SONG Z G, LIN Y C, LV R L, et al. Research on UAV autonomous deformation strategy based on deep learning[C]//Proceeding of the 5th International Symposium on Autonomous Systems (ISAS). Piscataway: IEEE Press, 2022: 1-7. [8] Mnih V, Kavukcuoglu K, Silver D, et al. Playing atari with deep reinforcement learning[J/OL]. arXiv preprint, [2013-12-19]. http://doi.org/10.48550/arXiv.1312.5602 [9] VAN HASSELT H, GUEZ A, SILVER D. Deep reinforcement learning with double Q-learning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2016, 30(1): 2094-2100. [10] WANG Z, SCHAUL T, HESSEL M, et al. Dueling network architectures for deep reinforcement learning[C]//Proceedings of the International Conference on Machine Learning. New York: ICML, 2016: 1995-2003. [11] SCHULMAN J, LEVINE S, ABBEEL P, et al. Trust region policy optimization[C]//Proceedings of the International Conference on Machine Learning. New York: ICML, 2015: 1889-1897. [12] SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. (2017-08-28)[2023-10-23]. http://arxiv.org/abs/1707.06347. [13] LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[C]//Proceedings of 4th International Conference on Learning Representations.Washington, D.c.: ICIR, 2016. [14] KONDA V, TSITSIKLIS J. Actor-critic algorithms[J]. Advances in Neural Information Processing Systems, 1999, 12: 1008-1014. [15] 马少捷, 惠俊鹏, 王宇航, 等. 变形飞行器深度强化学习姿态控制方法研究[J]. 航天控制, 2022, 40(6): 3-10. doi: 10.3969/j.issn.1006-3242.2022.06.001MA S J, HUI J P, WANG Y H, et al. Research on attitude control method of morphing aircraft based on deep reinforcement learning[J]. Aerospace Control, 2022, 40(6): 3-10 (in Chinese). doi: 10.3969/j.issn.1006-3242.2022.06.001 [16] LI B, YANG Z P, CHEN D Q, et al. Maneuvering target tracking of UAV based on MN-DDPG and transfer learning[J]. Defence Technology, 2021, 17(2): 457-466. doi: 10.1016/j.dt.2020.11.014 [17] LI R Z, WANG Q, LIU Y-A, et al. Morphing strategy design for UAV based on prioritized sweeping reinforcement learning[C]//Proceedings of the 46th Annual Conference of the IEEE Industrial Electronics Society. Piscataway: IEEE Press, 2020: 2786-2791. [18] 仇靖雯, 何真, 黄赞. 四翼变掠角飞行器模糊建模及受约束飞行控制[J]. 飞行力学, 2023, 41(4): 10-18.QIU J W, HE Z, HUANG Z. Fuzzy modeling and constrained flight control of four-wing variable sweep aircraft[J]. Flight Dynamics, 2023, 41(4): 10-18, 28 (in Chinese). [19] 高良. 弹射式变掠角串置翼飞行机器人设计及控制方法研究[D]. 哈尔滨: 哈尔滨工业大学, 2020.GAO L. Research on design and control of catapult launched tandem-wing flying robot with variable sweep[D]. Harbin: Harbin Institute of Technology, 2020(in Chinese). [20] 杨惟轶, 白辰甲, 蔡超, 等. 深度强化学习中稀疏奖励问题研究综述[J]. 计算机科学, 2020, 47(3): 182-191. doi: 10.11896/jsjkx.190200352YANG W Y, BAI C J, CAI C, et al. Survey on sparse reward in deep reinforcement learning[J]. Computer Science, 2020, 47(3): 182-191(in Chinese). doi: 10.11896/jsjkx.190200352 [21] KIM J J, CHA S H, RYU M, et al. Pre-training framework for improving learning speed of reinforcement learning based autonomous vehicles[C]//Proceedings of the International Conference on Electronics, Information, and Communication. Piscataway: IEEE Press, 2019: 1-2. [22] YU Y, SI X S, HU C H, et al. A review of recurrent neural networks: LSTM cells and network architectures[J]. Neural Computation, 2019, 31(7): 1235-1270. doi: 10.1162/neco_a_01199 [23] CHAO W, HAN D W, JIE X W. Multi-rotor UAV autonomous tracking and obstacle avoidance based on improved DDPG[C]// Proceedings of the 2nd International Conference on Artificial Intelligence and Computer Engineering. Piscataway: IEEE Press, 2021: 261-267. -

 下载:
下载:













 点击查看大图
点击查看大图

计量
- 文章访问数: 279
- HTML全文浏览量: 85
- PDF下载量: 1
- 被引次数: 0
