



-
摘要:
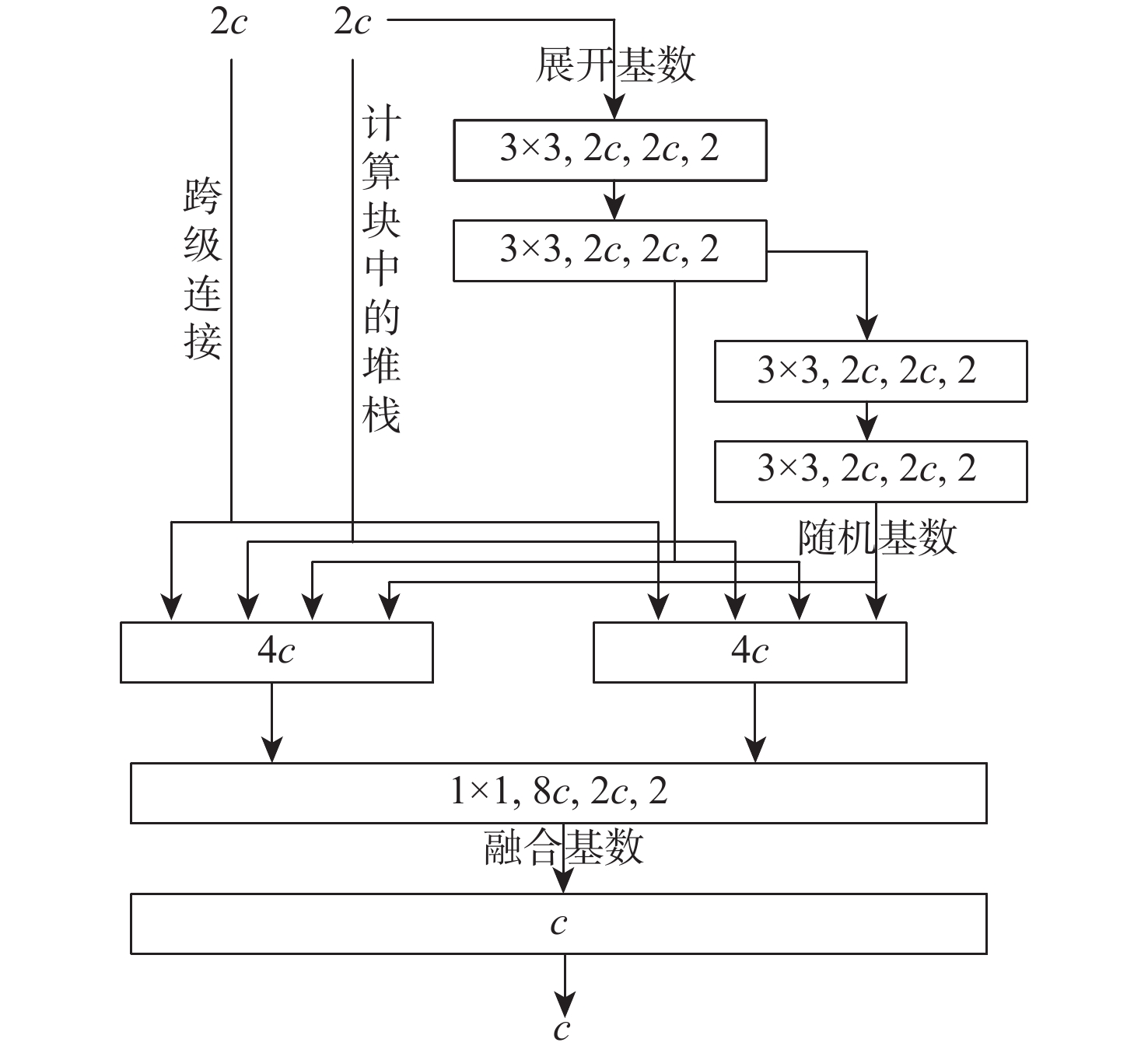
针对目前检测技术在航拍小目标检测任务中存在的漏检率和误检率较高的问题,提出一种基于改进YOLOv7的航拍小目标检测方法。在主干网络中加入CBAM融合注意力机制,将特征图在空间和通道两方面合理分配网络权重,抑制背景干扰,提升检测精度;引入一种用于低分辨率图像和小目标细化检测的SPD-Conv模块,消除原有卷积模块的跨卷积层和池化层,解决了原始卷积模块中存在的细粒度信息丢失以及对于特征表示学习效率较低的问题;在处理后的DOTA航拍数据集上进行性能评估。实验结果表明:改进的YOLOv7算法在处理后的DOTA航拍数据集上准确率
P 达到83.7%,召回率R 达到78.2%,均值平均精度mAP50达到81.5%,比原始YOLOv7算法精度提升了3.1%。说明所提算法可以有效降低漏检和错检率,具有良好性能。Abstract:This paper proposes an improved YOLOv7-based aerial small target detection method to address the high rates of missed and false detections in current detection technologies for aerial small target detection tasks. First, a CBAM fusion attention mechanism is incorporated into the backbone network, allocates weights reasonably in both spatial and channel-wise of the feature map, suppresses background interference and improves detection accuracy. The second is the SPD-Conv module, which removes the original convolutional module's cross-convolutional and pooling layers, improves feature representation learning efficiency, and mitigates fine-grained information loss in low-resolution images and small targets refinement detection. Finally, the improved YOLOv7 is evaluated on a processed DOTA aerial dataset. According to the results, it outperforms the original YOLOv7 by 3.1%, achieving 83.7% precision, 78.2% recall, and 81.5% average accuracy on the dataset. The improved algorithm effectively reduces missed and false detections, demonstrating a strong performance.
-
Key words:
- YOLOv7 /
- small target detection /
- attention mechanism /
- convolutional neural network /
- computer vis
-
表 1 实验评估指标对比
Table 1. Comparison of experimental evaluation indicators
% 模型 P R mAP50 Y 83.0 75.4 78.4 YS 83.2 76.6 79.8 YC 83.6 78.0 80.7 YSC 83.7 78.2 81.5  下载: 导出CSV
下载: 导出CSV
表 3 DOTA 数据集上主要类别目标检测精度
Table 3. Accuracy of target detection for each category on the DOTA dataset
% 模型 Plane Baseball-diamond Helicopter Roundabout Tennis-court Harbor Large-vehicle Basketball-court Ship YOLOv7 92.4 86.2 72.6 64.9 92.4 83.7 89.4 87.2 89.0 OURS 96.7 88.9 77.8 70.2 95.8 87.7 91.3 88.1 88.8
下载: 导出CSV
-
[1] NAJIBI M, SAMANGOUEI P, CHELLAPPA R, et al. SSH: single stage headless face detector[C]//Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 4885-4894. [2] ZHANG L L, LIN L, LIANG X D, et al. Is faster R-CNN doing well for pedestrian detection?[C]//Proceedings of the European Conference on Computer Vision– ECCV 2016. Berlin: Springer, 2016: 443-457. [3] RAGHUNANDAN A, Mohana, RAGHAV P, et al. Object detection algorithms for video surveillance applications[C]//Proceedings of the 2018 International Conference on Communication and Signal Processing. Piscataway: IEEE Press, 2018: 563-568. [4] UIJLINGS J R R, VAN DE SANDE K E A, GEVERS T, et al. Selective search for object recognition[J]. International Journal of Computer Vision, 2013, 104(2): 154-171. doi: 10.1007/s11263-013-0620-5 [5] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 779-788. [6] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 6517-6525. [7] REDMON J, FARHADI A. Yolov3: an incremental improvement [EB/OL]. (2018-04-08)[2021-03-25]. http://arxiv.org/10.48550/arxiv.1804.02767. [8] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. Yolov4: optimal speed and accuracy of object detection[EB/OL]. (2020-04-23)[2021-04-15]. http://arxiv.org/abs/2004.10934. [9] WANG C Y, BOCHKOVSKIY A, LIAO H M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2023: 7464-7475. [10] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]//Proceedings of the Computer Vision – ECCV 2018. Berlin: Springer, 2018: 3-19. [11] SUNKARA R, LUO T. No more strided convolutions or pooling: a new CNN building block for low-resolution images and small objects[EB/OL]. (2022-08-07)[2022-08-21]. http://arxiv.org/abs/2208.03641v1. [12] XIA G S, BAI X, DING J, et al. DOTA: a large-scale dataset for object detection in aerial images[C]//Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 3974-3983. [13] CHEN Y C, ZHENG W S, LAI J H, et al. An asymmetric distance model for cross-view feature mapping in person reidentification[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 27(8): 1661-1675. doi: 10.1109/TCSVT.2016.2515309 [14] Zhao H, Shi J, Qi X, et al. Pyramid scene parsing network[EB/OL]. (2014-04-27)[2022-08-22]. http://doi.org/10.48550/arxiv.1612.01105. [15] BERG A C, FU C Y, SZEGEDY C, et al. SSD: single shot MultiBox detector[EB/OL]. (2015-03-30)[2023-09-16]. http://doi.org/10.1007/978-3-319-46448-0_2. -

 下载:
下载:












 点击查看大图
点击查看大图
计量
- 文章访问数: 371
- HTML全文浏览量: 104
- PDF下载量: 52
- 被引次数: 0
