



Key points detection method for civil aircraft pilot in complex lighting environments
-
摘要:
基于计算机视觉技术对民用飞机飞行员操纵行为进行识别和监控,对于确保民用航空运行安全具有重要的现实意义。提出一种复杂光照环境下的飞行员关键点检测方法。鉴于民用飞机驾驶舱复杂光照环境,提出图像亮度调节模块,该模块分级判断图像亮度均值,实现不同亮度图像特征融合,提升运行速度,并最大化保留图像细节特征;鉴于较多的关键点定位是精确行为识别的基础,提出轻量化的飞行员肢体关键点和手部关键点检测网络,该网络在高分辨率分支运用次序交换注意力模块,以缓解原始视觉注意力计算成本随输入分辨率增加呈二次增长的问题,联合部署飞行员肢体和手部关键点检测网络,选择典型的飞行动作进行实验验证;进行大量消融实验,定量和定性地探讨不同组件(图像亮度调节模块、次序交换注意力模块)对模型性能的影响,建立所提方法与预测结果之间的可解释关系。提出的模型在飞行员关键点检测数据集和MS COCO val2017 数据集上的 AP 分别达到 81.9% 和 72.8%,兼顾精度和实时性。
Abstract:The recognition and monitoring of pilot maneuvering behaviors in civil aircraft based on computer vision is of great practical significance to ensure the safety of civil aviation operations. In this paper, a pilot key point detection model in complex lighting environments is proposed. Firstly, considering the complex lighting environment in the cockpit of civil aircraft, an image brightness adjustment module is proposed. This module increases the retention of image detail features while simultaneously increasing operation speed by hierarchically determining the average value of image brightness and achieving the fusion of image features of varying brightness. Second, given that a higher number of key point localizations are fundamental to accurate behavior recognition, a lightweight pilot limb key point, and hand key point detection network is proposed. The network employs a sequential exchange of attention modules in the high-resolution branch to alleviate the problem of quadratic growth of the computational cost of raw vision attention with increasing input resolution. In addition, the pilot limb and hand key points detection networks are jointly deployed and typical flight maneuvers are selected for experimental validation. In order to establish an interpretable relationship between the methodology and the prediction results, comprehensive ablation experiments are finally carried out to investigate both quantitatively and qualitatively the effects of various components (image brightness adjustment module, order exchange attention module) on the model performance. The proposed model achieves an AP of 81.9% on the pilot limb key point dataset and 72.8% on the MS COCO val 2017 dataset, balancing accuracy and real-time performance.
-
Key words:
- civil aircraft /
- intelligent cockpit /
- complex lighting /
- pilot /
- key points detection /
- vision attention
-
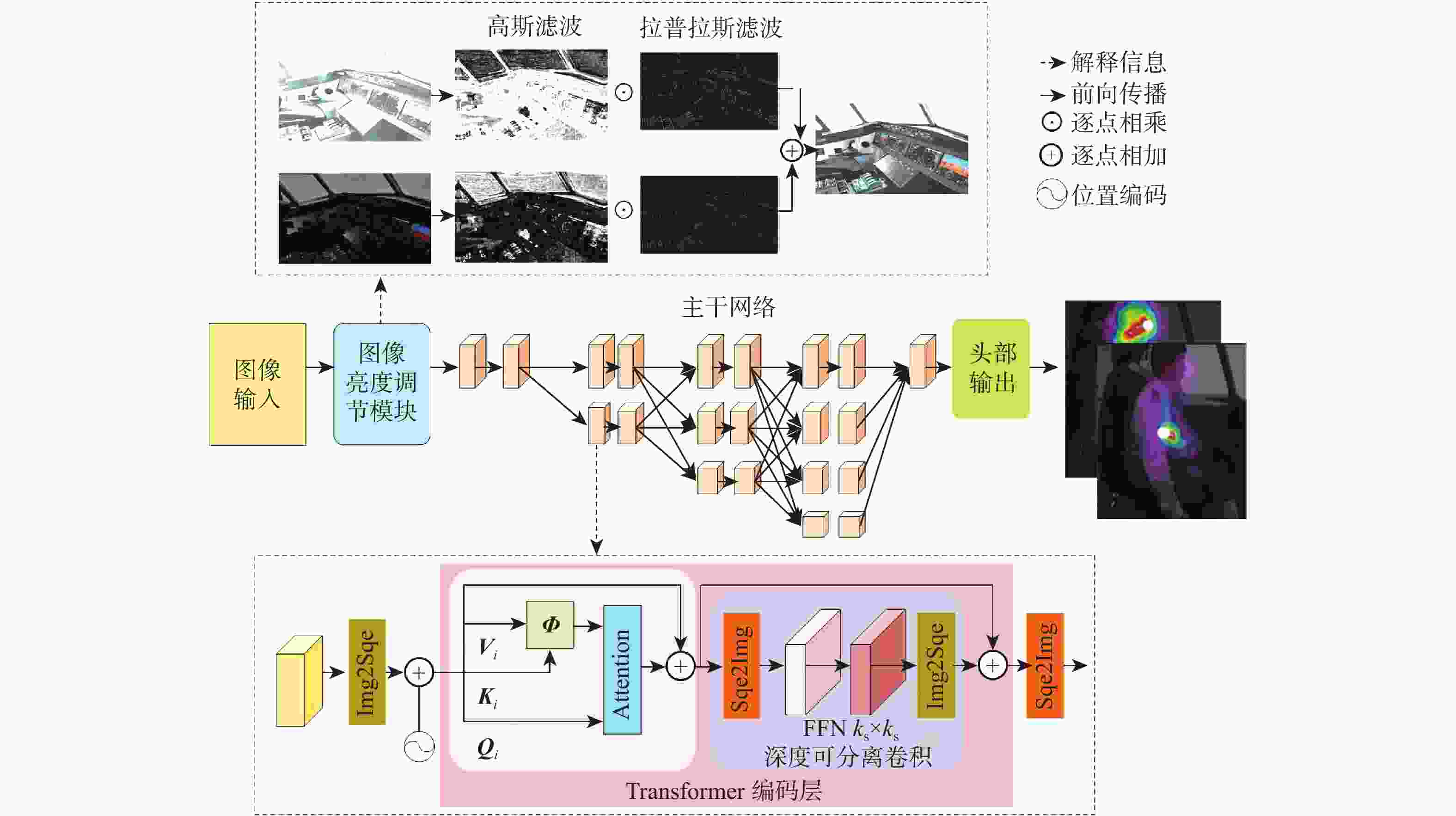
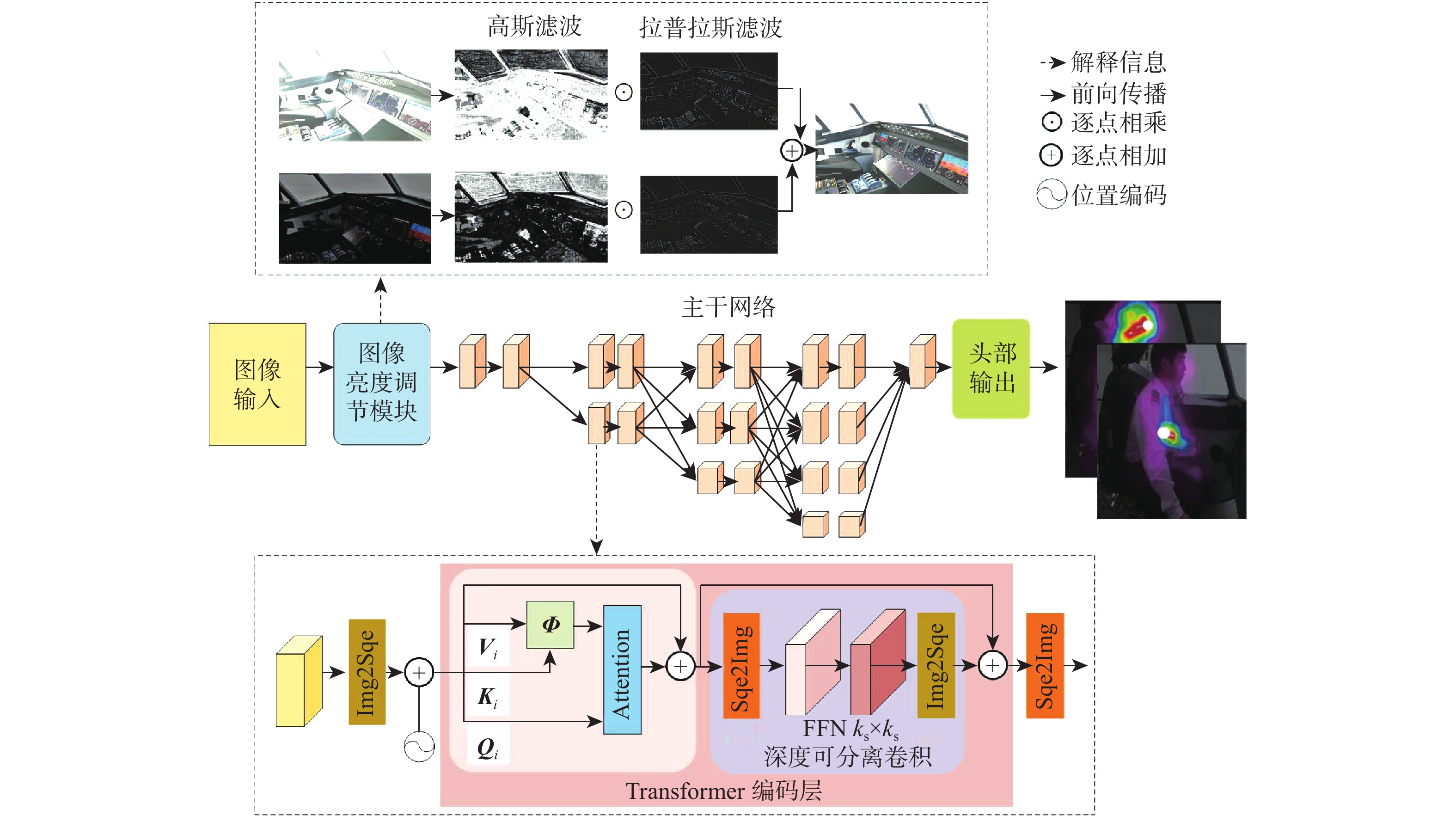
图 4 面向复杂光照环境飞行员肢体关键点检测整体架构
Figure 4. Overall architecture of pilot limb key points detection for complex lighting environment

图 7 飞行员肢体和手部关键点联合检测的可视化效果
Figure 7. Visualisation of the joint detection of key points of the pilot’s limb and hands
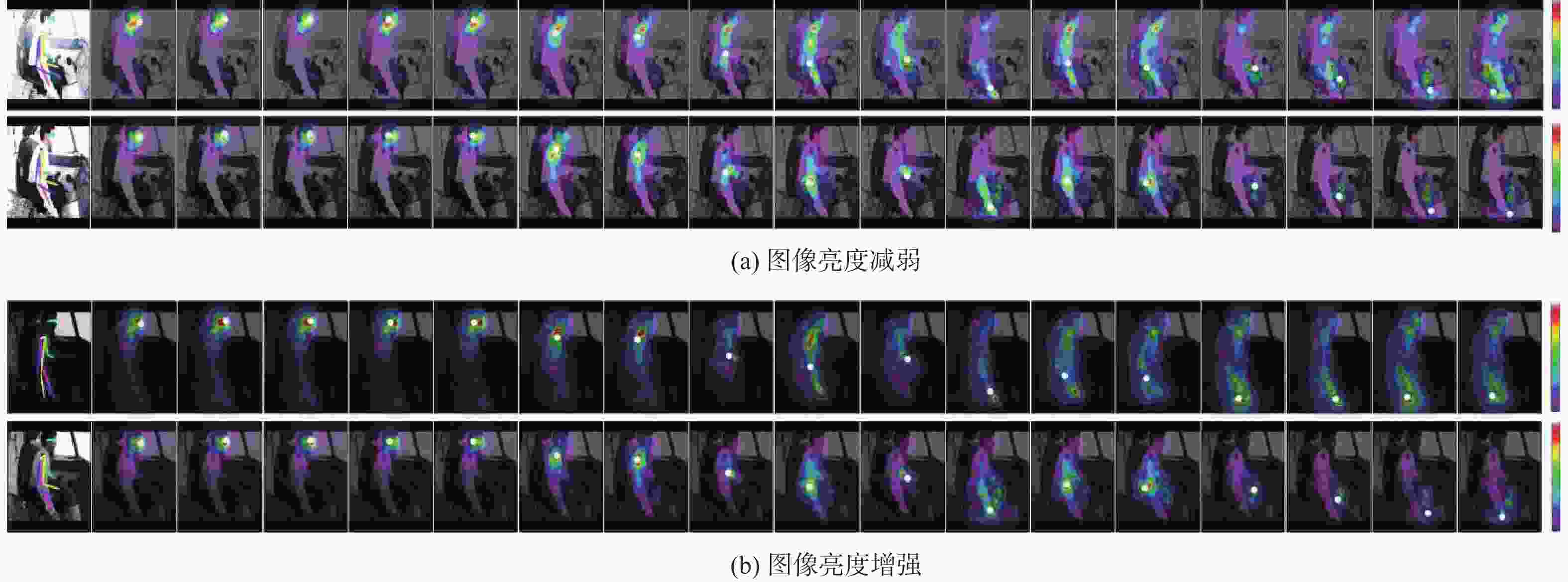
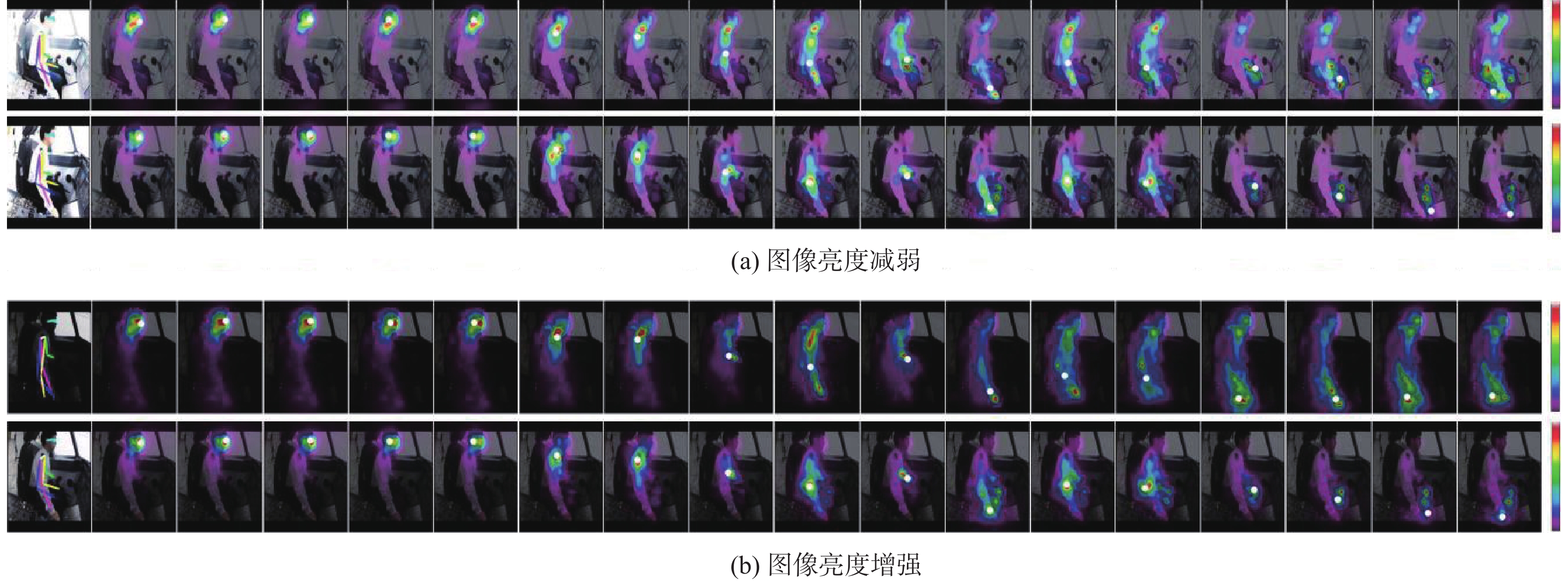
图 9 图像亮度调节模块下的飞行员肢体关键点输出比较
Figure 9. Comparison of pilot limb key point outputs under the image brightness adjustment module
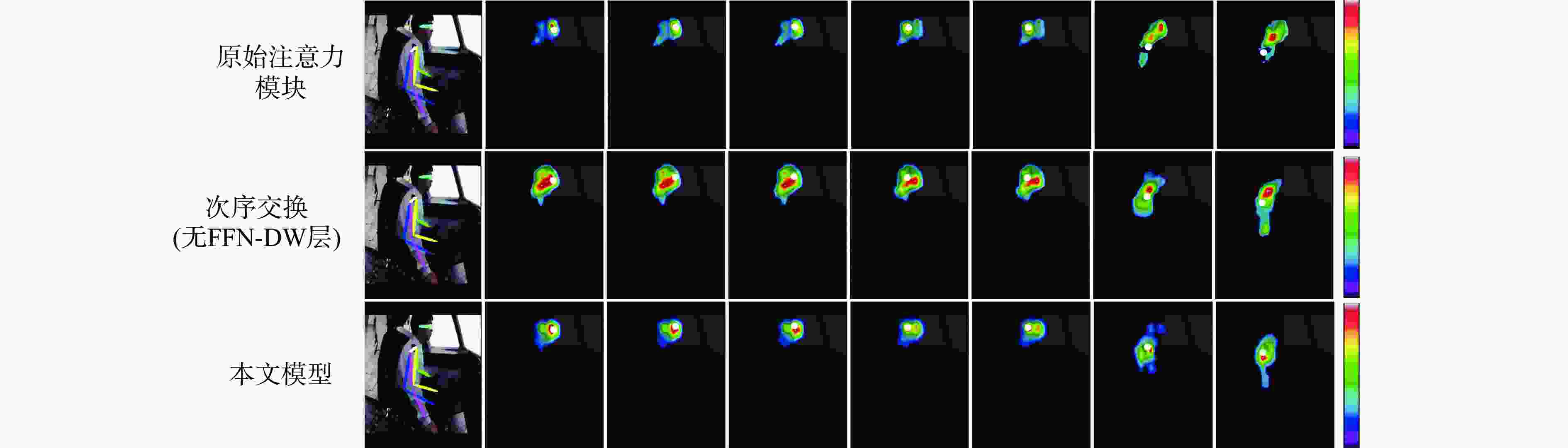
图 10 不同模型在飞行员关键点定位的可视化结果
Figure 10. Visualisation of pilot key point detection results with different models
表 1 HRNet-Former主干结构
Table 1. HRNet-Former backbone structure
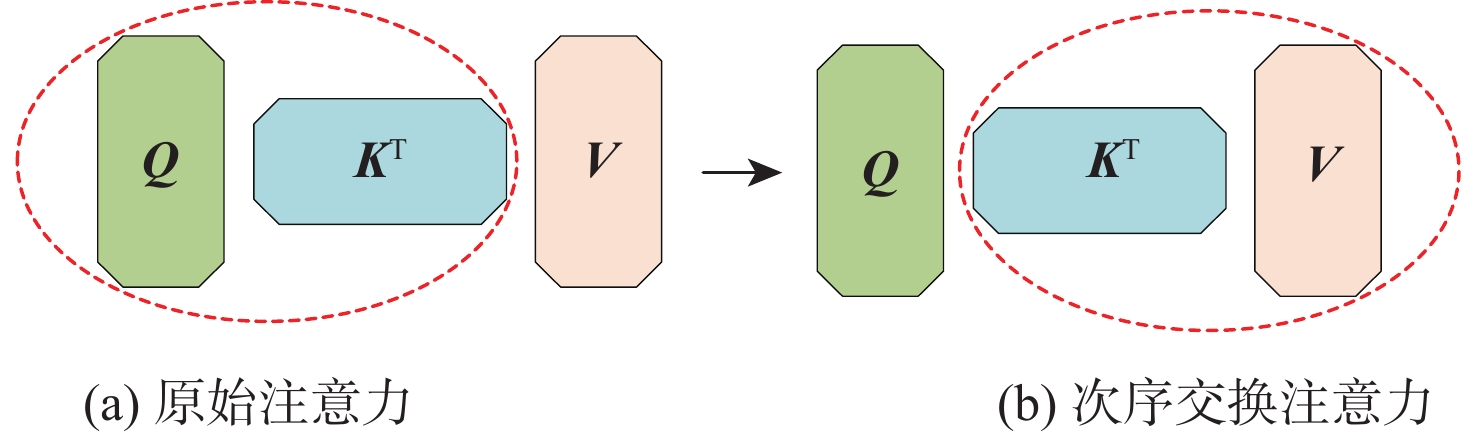
尺寸 阶段1 阶段2 阶段3 阶段4 64 × 48 $ \left[\begin{array}{l}1\times 1,64\\ 3\times 3,64\\ 1\times 1,256\end{array}\right] $×2 $ \left[\begin{array}{l}次序交换注意力模块,\text{32}\\ 头\text{=1},深度线性模块=\text{7}\times \text{7}\end{array}\right] $×2 $ \left[\begin{array}{l}次序交换注意力模块,\text{32}\\ 头\text{=1},深度线性模块=\text{7}\times \text{7}\end{array}\right] $×2 $ \left[\begin{array}{l}次序交换注意力模块,\text{32}\\ 头\text{=1},深度线性模块=\text{7}\times \text{7}\end{array}\right] $×2 32 × 24 $ \left[\begin{array}{l}次序交换注意力模块,64\\ 头\text{=1},深度线性模块=\text{7}\times \text{7}\end{array}\right] $×2 $ \left[\begin{array}{l}次序交换注意力模块,64\\ 头\text{=1},深度线性模块=\text{7}\times \text{7}\end{array}\right] $×2 $ \left[\begin{array}{l}次序交换注意力模块,64\\ 头\text{=1},深度线性模块=\text{7}\times \text{7}\end{array}\right] $×2 16 × 12 $ \left[\begin{array}{l}次序交换注意力模块,\text{128}\\ 头\text{=2},深度线性模块=\text{5}\times \text{5}\end{array}\right] $×2 $ \left[\begin{array}{l}次序交换注意力模块,\text{128}\\ 头\text{=2},深度线性模块=\text{5}\times \text{5}\end{array}\right] $×2 8 × 6 $ \left[\begin{array}{l}原始注意力模块,\text{256} \\ 头\text{=4}\end{array}\right] $×2  下载: 导出CSV
下载: 导出CSV
表 2 不同模型在飞行员肢体关键点检测数据集上的性能比较
Table 2. Performance comparison of different models on the pilot limb key point detection dataset
模型 主干网络 输入尺寸/(像素×像素) 参数量 浮点运算速度/(109 s−1) AP/% AR/% SimpleBaseline[34] ResNet-50 256×192 34.0×106 8.9 77.9 78.5 HRNet[20] HRNet-W32 256×192 28.5×106 7.1 80.8 81.6 TransPose[24] HRNet-W32 256×192 8.0×106 10.2 81.3 83.2 PoseUR[35] HRFormer-B 256×192 28.8×106 12.6 82.1 83.8 HRFormer[22] HRFormer-S 256×192 2.5×106 1.3 80.6 82.2 本文 HRNet-Former 256×192 4.5×106 3.8 81.9 83.3
下载: 导出CSV
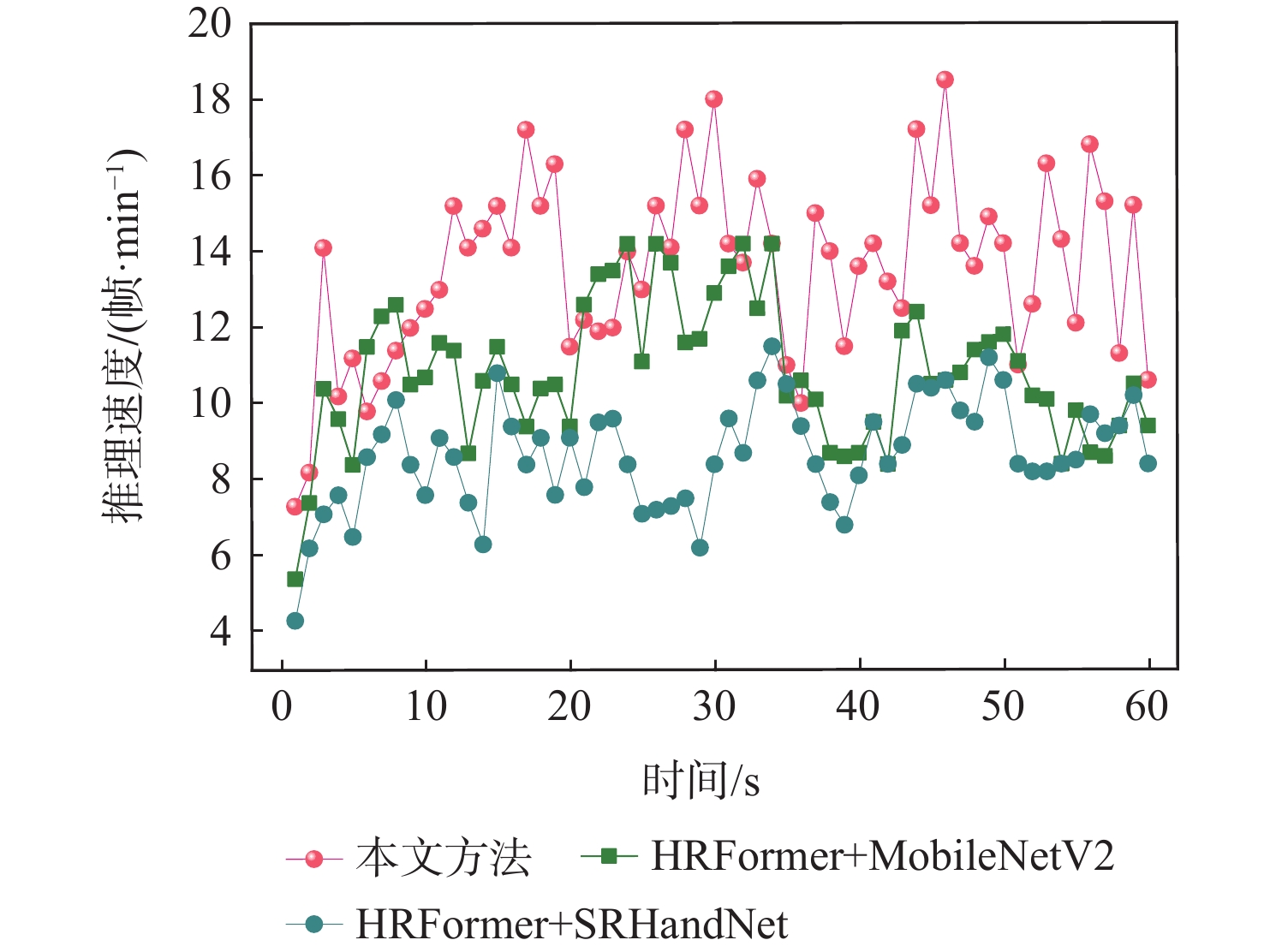
表 3 不同模型推理速度比较
Table 3. Comparison of the inference speed of reasoning for different models
下载: 导出CSV
表 4 不同模型在MS COCO val2017数据集的性能比较
Table 4. Performance comparison of the different models on MS COCO val2017 dataset
模型类型 模型 输入尺寸/(像素×像素) 参数量 浮点运算速度/(109 s−1) AP/% AR/% 复杂网络模型 CPN[19] 256×192 27.0×106 6.2 68.6 SimpleBaseline[34] 256×192 34.0×106 8.9 70.4 76.3 HRNet[20] 256×192 28.5×106 7.1 73.4 78.9 DAEK[21] 128×96 63.6×106 3.6 71.9 77.9 TransPose[24] 256×192 8.0×106 10.2 74.2 78.0 PoseUR[35] 256×192 28.8×106 4.48 74.7 轻量网络模型 MobileNetV2[36] 256×192 9.6×106 1.48 64.6 70.7 ShuffleNetV2[37] 256×192 7.6×106 1.28 59.9 66.4 Lite-HRNet-18[38] 256×192 1.1×106 0.2 64.8 71.2 HRFormer[22] 256×192 2.5×106 1.3 70.9 76.6 本文 256×192 4.5×106 3.8 72.8 78.4
下载: 导出CSV
表 6 联合模型的实时性比较
Table 6. Real-time comparison for joint models
联合模型(肢体+手部) 参数量 推理速度/(帧·min−1) HRNet+MobileNetV2 38.1×106 7.6 HRFormer+MobileNetV2 12.1×106 11.2 HRNet+ShuffleNetV2 36.1×106 7.4 HRFormer+ShuffleNetV2 10.1×106 11.1 HRNetV1+SRHandNet 44.8×106 5.4 HRFormer+SRHandNet 18.8×106 8.8 本文 9.7×106 14.3
下载: 导出CSV
表 7 图像亮度调节前后模型性能比较
Table 7. Comparison of model performance before and after image brightness adjustment
图像亮度调节 输入尺寸/
(像素×像素)AP/% 推理速度/
(帧·min−1)原始图像(曝光) 256×192 74.2 25.1 经过图像调节模块(曝光) 256×192 84.6 25.1 原始图像(弱光) 256×192 75.3 26.3 经过图像调节模块(弱光) 256×192 83.1 26.3
下载: 导出CSV
表 8 不同模型在飞行员肢体关键点数据集上的性能比较
Table 8. Performance comparison of different models on the pilot’s limb key point dataset
模型 参数量 浮点运算
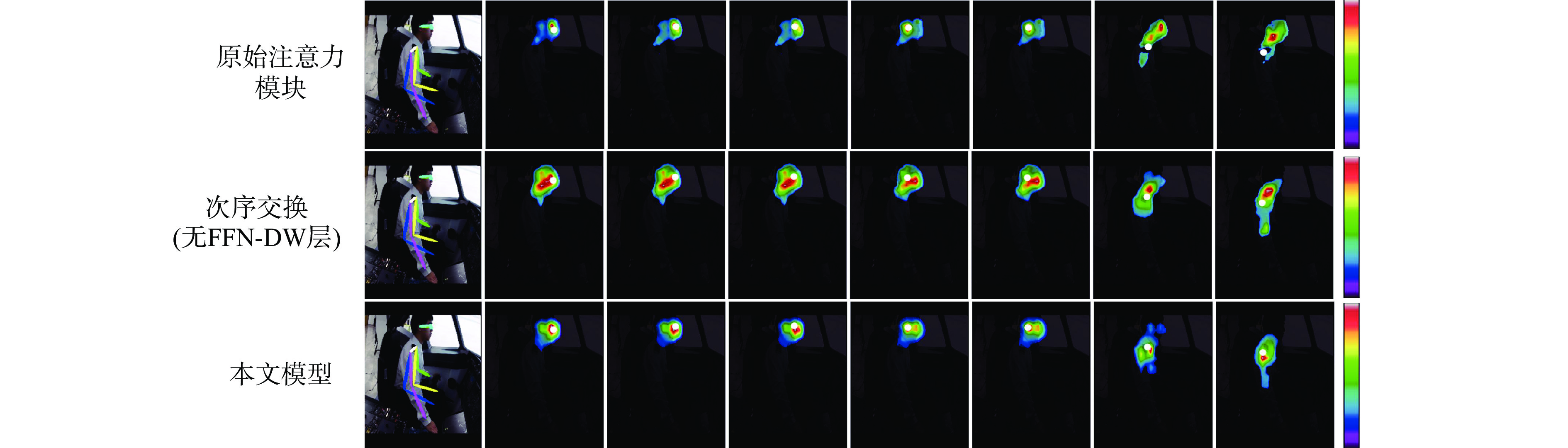
速度/(109 s−1)AP/% 推理速度/
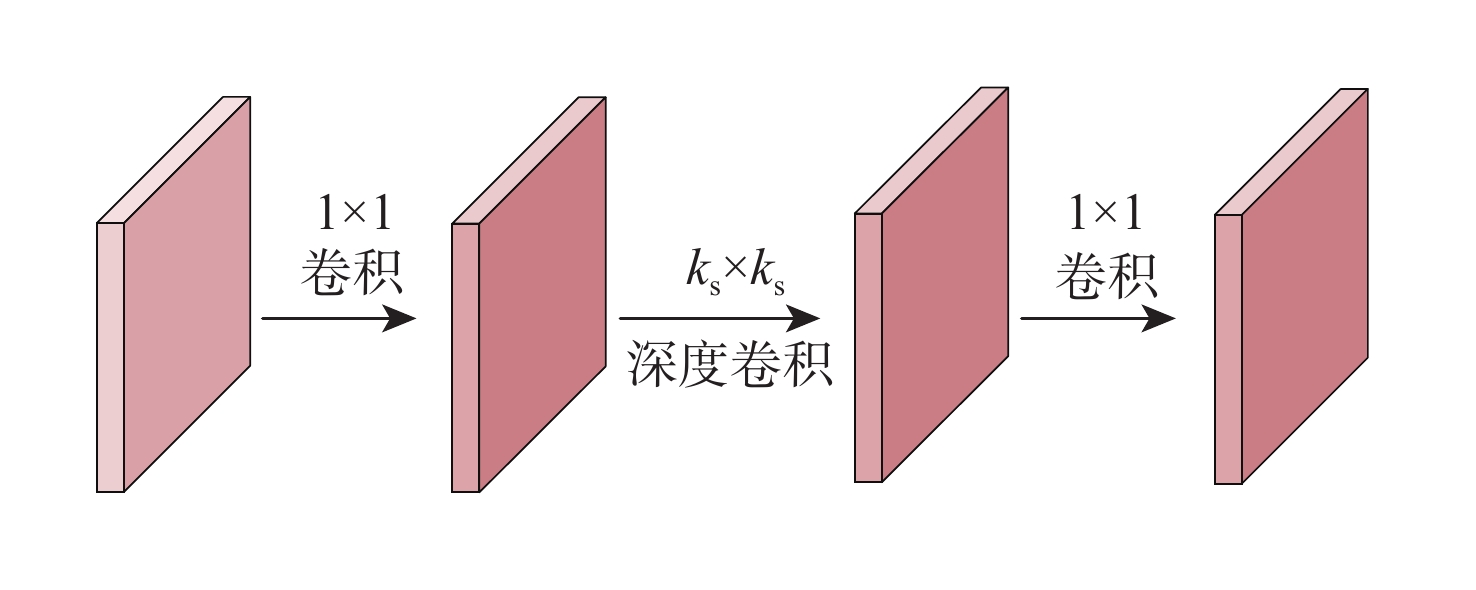
(帧·min−1)原始注意力模块 5.0×106 8.56 82.2 21.3 次序交换(无FFN-DW层) 4.1×106 3.34 74.4 39.7 本文 4.5×106 3.80 82.3 35.4
下载: 导出CSV
-
[1] 杨志刚, 张炯, 李博, 等. 民用飞机智能飞行技术综述[J]. 航空学报, 2021, 42(4): 525198.YANG Z G, ZHANG J, LI B, et al. Reviews on intelligent flight technology of civil aircraft[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(4): 525198(in Chinese). [2] LIANG B H, CHEN Y, WU H. A conception of flight test mode for future intelligent cockpit[C]//Proceedings of the Chinese Automation Congress. Piscataway: IEEE Press, 2020: 3260-3264. [3] JIN Z B, LI D C, XIANG J W. Robot pilot: a new autonomous system toward flying manned aerial vehicles[J]. Engineering, 2023, 27: 242-253. doi: 10.1016/j.eng.2022.10.018 [4] KELLY D, EFTHYMIOU M. An analysis of human factors in fifty controlled flight into terrain aviation accidents from 2007 to 2017[J]. Journal of Safety Research, 2019, 69: 155-165. doi: 10.1016/j.jsr.2019.03.009 [5] DE SANT’ANNA D A L M, DE HILAL A V G. The impact of human factors on pilots’ safety behavior in offshore aviation companies: a Brazilian case[J]. Safety Science, 2021, 140: 105272. doi: 10.1016/j.ssci.2021.105272 [6] WANG A G, CHEN H H, ZHENG C D, et al. Evaluation of random forest for complex human activity recognition using wearable sensors[C]//Proceedings of the International Conference on Networking and Network Applications. Piscataway: IEEE Press, 2020: 310-315. [7] YAN S J, XIONG Y J, LIN D H. Spatial temporal graph convolutional networks for skeleton-based action recognition[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2018, 32(1): 7444-7452. [8] KIM Y T. Contrast enhancement using brightness preserving bi-histogram equalization[J]. IEEE Transactions on Consumer Electronics, 1997, 43(1): 1-8. doi: 10.1109/30.580378 [9] LAND E H, MCCANN J J. Lightness and retinex theory[J]. Journal of the Optical Society of America, 1971, 61(1): 1. doi: 10.1364/JOSA.61.000001 [10] SHEN L, YUE Z H, FENG F, et al. MSR-net: low-light image enhancement using deep convolutional network[EB/OL]. (2017-11-07)[2023-09-01]. http://arxiv.org/abs/1711.02488. [11] WEI C, WANG W, YANG W, et al. Deep retinex decomposition for low-light enhancement[EB/OL]. (2018-08-14)[2023-09-01]. http://arxiv.org/abs/1808.04560. [12] YASARLA R, SINDAGI V A, PATEL V M. Semi-supervised image deraining using Gaussian processes[J]. IEEE Transactions on Image Processing, 2021, 30: 6570-6582. doi: 10.1109/TIP.2021.3096323 [13] LV F F, LIU B, LU F. Fast enhancement for non-uniform illumination images using light-weight CNNs[C]//Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020: 1450-1458. [14] KANSAL S, PURWAR S, TRIPATHI R K. Image contrast enhancement using unsharp masking and histogram equalization[J]. Multimedia Tools and Applications, 2018, 77(20): 26919-26938. doi: 10.1007/s11042-018-5894-8 [15] RAO B S. Dynamic histogram equalization for contrast enhancement for digital images[J]. Applied Soft Computing, 2020, 89: 106114. doi: 10.1016/j.asoc.2020.106114 [16] YUAN L, SUN J. Automatic exposure correction of consumer photographs[C]//Proceedings of the Computer Vision-ECCV. Berlin: Springer, 2012: 771-785. [17] ZHANG J A, LIU R S, MA L, et al. Principle-inspired multi-scale aggregation network for extremely low-light image enhancement[C]//Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2020: 2638-2642. [18] 孔英会, 秦胤峰, 张珂. 深度学习二维人体姿态估计方法综述[J]. 中国图象图形学报, 2023, 28(7): 1965-1989. doi: 10.11834/jig.220436KONG Y H, QIN Y F, ZHANG K. Deep learning based two-dimension human pose estimation: a critical analysis[J]. Journal of Image and Graphics, 2023, 28(7): 1965-1989(in Chinese). doi: 10.11834/jig.220436 [19] CHEN Y L, WANG Z C, PENG Y X, et al. Cascaded pyramid network for multi-person pose estimation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7103-7112. [20] SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 5686-5696. [21] BULAT A, KOSSAIFI J, TZIMIROPOULOS G, et al. Toward fast and accurate human pose estimation via soft-gated skip connections[C]//Proceedings of the 15th IEEE International Conference on Automatic Face and Gesture Recognition. Piscataway: IEEE Press, 2020: 8-15. [22] YUAN Y H, FU R, HUANG L, et al. HRFormer: high-resolution Transformer for dense prediction[EB/OL]. (2021-11-07)[2023-09-01]. http://arxiv.org/abs/2110. 09408. [23] XIONG Z N, WANG C X, LI Y, et al. Swin-Pose: swin Transformer based human pose estimation[C]//Proceedings of the IEEE 5th International Conference on Multimedia Information Processing and Retrieval. Piscataway: IEEE Press, 2022: 228-233. [24] YANG S, QUAN Z B, NIE M, et al. TransPose: keypoint localization via Transformer[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 11782-11792. [25] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[EB/OL]. (2021-06-03)[2023-09-01]. http://arxiv.org/abs/2010.11929. [26] LIN K, WANG L J, LIU Z C. End-to-end human pose and mesh reconstruction with Transformers[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 1954-1963. [27] 刘豪, 吴红兰, 房宇轩. 结合全局上下文信息的高效人体姿态估计[J]. 计算机工程, 2023, 49(7): 102-109.LIU H, WU H L, FANG Y X. Efficient human pose estimation combining global contextual information[J]. Computer Engineering, 2023, 49(7): 102-109(in Chinese). [28] CAI H, LI J Y, HU M Y, et al. EfficientViT: multi-scale linear attention for high-resolution dense prediction[EB/OL]. (2024-02-06)[2023-09-01]. http://arxiv.org/abs/2205.14756. [29] XU W J, XU Y F, CHANG T, et al. Co-scale conv-attentional image Transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 9961-9970. [30] OGDEN J M, ADELSON E H, BERGEN J R, et al. Pyramid-based computer graphics[J]. RCA Engineer, 1985, 30(5): 4-15. [31] ZHU X K, LYU S C, WANG X, et al. TPH-YOLOv5: improved YOLOv5 based on Transformer prediction head for object detection on drone-captured scenarios[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 2778–2788. [32] 吴红兰, 刘豪, 孙有朝. 基于视觉Transformer飞行员姿态估计[J]. 北京麻豆精品秘 国产传媒学报, 2024, 50(10): 3100-3110.WU H L, LIU H, SUN Y C. Vision Transformer-based pilot pose estimation[J]. Journal of Beijing University of Aeronautics and Astronautics, 2024, 50(10): 3100-3110(in Chinese). [33] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]//Proceedings of the Computer Vision-ECCV. Berlin: Springer, 2014: 740-755. [34] XIAO B, WU H P, WEI Y C. Simple baselines for human pose estimation and tracking[C]//Proceedings of the Computer Vision-ECCV. Berlin: Springer, 2018: 472-487. [35] MAO W A, GE Y T, SHEN C H, et al. PoseUR: direct human pose regression with Transformers[C]//Proceedings of the Computer Vision-ECCV. Berlin: Springer, 2022: 72-88. [36] SANDLER M, HOWARD A, ZHU M L, et al. MobileNetV2: inverted residuals and linear bottlenecks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 4510-4520. [37] MA N N, ZHANG X Y, ZHENG H T, et al. ShuffleNet V2: practical guidelines for efficient CNN architecture design[C]//Proceedings of the Computer Vision-ECCV. Berlin: Springer, 2018: 122-138. [38] YU C Q, XIAO B, GAO C X, et al. Lite-HRNet: a lightweight high-resolution network[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 10435-10445. [39] ZIMMERMANN C, CEYLAN D, YANG J M, et al. FreiHAND: a dataset for markerless capture of hand pose and shape from single RGB images[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 813-822. [40] WANG Y G, ZHANG B W, PENG C. SRHandNet: real-time 2D hand pose estimation with simultaneous region localization[J]. IEEE Transactions on Image Processing, 2020, 29: 2977-2986. doi: 10.1109/TIP.2019.2955280 -

 下载:
下载:




 点击查看大图
点击查看大图

计量
- 文章访问数: 230
- HTML全文浏览量: 81
- PDF下载量: 1
- 被引次数: 0
